
Chapter 16 Cargo and data storage
In the beginning, there was Semantic MediaWiki. Semantic MediaWiki (SMW) was an extension developed in 2005 that allowed you to store, and query, data within a wiki. In retrospect, it was not an ideal solution, and it had a lot of structural problems, but it worked, and for a while it was the only solution, so no one had to think too much about whether to use it: if you wanted data reuse and cool visualizations within your wiki, you needed Semantic MediaWiki. It got bonus points for including the word “semantic”, due to its basis in the Semantic Web, which at the time was a big buzzword in the tech world.
Not long afterwards, competitors started to appear: the first may have been the RecordAdmin extension in 2008, though it was not widely used and became unmaintained a few years later. At this point, there are at least five available alternatives: Wikibase (released in 2012), Cargo (2015), VisualData (2022), Bucket (2025) and NeoWiki (2026). (Wikibase, VisualData and NeoWiki also handle data editing, as did RecordAdmin; while the others are often used alongside the Page Forms extension for data editing.)
Most of this chapter deals with Cargo, which I am the main author of, and which I consider the best of these solutions. This chapter also covers Semantic MediaWiki (SMW), though, as well as Wikibase – which is especially important in the context of Wikidata. VisualData, Bucket and NeoWiki, while all interesting technically, at this point, get relatively minimal usage, although this of course may change in the future.
A little more should be said about Semantic MediaWiki here, though, since for a long time it was (and for some people, probably still is) synonymous with the concept of data storage in MediaWiki. Why relegate it to a relatively small section?
Well, SMW is, structurally, a mess. It is intended to store free-form “triples”, like a so-called triplestore would, and it can indeed store its data in a triplestore, but 99% of the time its data is stored in a relational database instead, which gives you the worst of both worlds: the lack of structure of a free-form graph database, and the slow and complex querying of a relational database attempting to mimic a triplestore. Its codebase is massive and buggy. To make full use of SMW requires installing about 15 (!) extensions: library-style extensions that SMW makes use of, as well as extensions that add necessary additional functionality, like Semantic Compound Queries. To use SMW requires learning a whole syntax for querying data, and requires creating and maintaining many (potentially thousands) of data structure wiki pages. And to really understand SMW requires understanding the idea of semantic triples, a foreign concept to most, and one that’s trickier than it first seems, especially when you get into multi-dimensional data.
Perhaps the ultimate knock against SMW, though, it that many of its main developers are currently at work on developing the NeoWiki extension – which is conceptually simpler, as each page’s data is simply stored as a piece of JSON, rather than in a combination of template calls, parser functions and custom syntax. Practically speaking, it’s unclear whether SMW will keep getting the development attention it needs; more generally, it’s hard to justify encouraging anyone to use SMW when even its core developers have moved on.
How Cargo works: an example
Let’s say you have a wiki about public art sculptures around the world. You’ve put in all the effort to carefully catalog thousands of sculptures, and now, on a whim, you want to see a list of all the sculptures in Kaunas, Lithuania created in the 19th century. On a typical wiki, whether it’s Wikipedia or anything else, you have essentially two options: you can compile such a list manually on some wiki page, or you can tag all such pages (assuming every sculpture has a separate page) with a category like “19th century sculptures in Kaunas, Lithuania”.
Both types of actions are done on Wikipedia all the time, and on many other wikis as well. However, they both have problems: the first option, manually compiling a list, takes a lot of work, and requires modifying the list each time a new page is added that belongs on that list (or when some error is discovered). In the second case, the list (on the category page) is generated automatically, but the category tags have to be added painstakingly to each page. And if you’re expecting users to do it, they need to be given precise instructions on how to add categories and what the categories should be named (should it be “Kaunas, Lithuania” or just “Kaunas”?), and in general, what the ideal data structure should be. Should there be a “19th century” category for each city covered in the wiki, even those with only one or two sculptures to their name? And, conversely, should cities with many 19th century sculptures have them further split up, say by the sculpture’s art style? Or should the style instead be tagged with a separate category? These are questions that do not necessarily have a single correct answer.
Cargo offers a solution to this problem. Instead of compiling lists, or having an overload of categories, you can define a single infobox template meant to be put on sculpture pages, which both displays all the relevant information (city, country, year, genre, subject matter, etc.) for each sculpture, and stores that information in a way that can be queried. So instead of having to manage a large and probably somewhat chaotic set of categories, you can keep the data structure simple, and move the complexity (such as there is) to the queries that display the data.
It should be noted that you probably would not have to create any query at all to get the specific list mentioned before - because Cargo provides an automatic drill-down interface that lets you click through values of different facets/fields to see the results for any specific combination you’re looking for.
And Cargo allows you to go beyond simply displaying page lists - for example, you can see all the information in a table, you can display statues on a map or timeline, and you can aggregate them by country, year, style etc. to show their breakdown.
What about the infoboxes - isn’t it still difficult for users to learn how to add and populate those? For that, one frequent solution is the Page Forms extension, covered in the next chapter, which provides forms so that users don’t need to deal with wikitext syntax in order to create and change data.
Storing data
The creation of data structures, and storage of data, is done in Cargo exclusively via templates. Any template that makes use of Cargo needs to contain calls to the parser functions #cargo_declare and #cargo_store; or, more rarely, calls to #cargo_attach and #cargo_store. #cargo_declare defines the fields for a table of data, #cargo_store stores data within that table, and #cargo_attach specifies that a template stores its data to a table that has been defined elsewhere.
Setting the Cargo database
By default, Cargo uses the standard MediaWiki database to hold its data; it differentiates its DB tables from all the rest by starting all their names with “cargo__”. You can instead have Cargo use a separate database. There are two main reasons why this may be a good idea: it’s potentially more secure for the main MediaWiki data (there are no known security problems in Cargo, but problems could possibly be discovered in the future), and it would prevent slow Cargo queries from interfering with the regular operation of the wiki.
Cargo offers the following global settings to let you use a separate database: $wgCargoDBtype, $wgCargoDBserver, $wgCargoDBname, $wgCargoDBuser, $wgCargoDBpassword, $wgCargoDBprefix. To use a custom database, you just need to set values for the first five variables in LocalSettings.php. (The sixth, for the prefix, is optional.)
Declaring a table
A template that stores data in a table needs to also either declare that table, or "attach" itself to a table that is declared elsewhere. Since there is usually one table per template and vice versa, most templates that make use of Cargo will declare their own table. Declaring is done via the parser function #cargo_declare. This function is called with the following syntax:
{{#cargo_declare:_table=table name|field_1=field description 1|field_2=field description 2...etc.}}
First, note that neither the table name nor field names can contain spaces; instead, you can use underscores, CamelCase, etc.
The field description must start with the type of the field, and in many cases it will simply be the type. The following types are predefined in Cargo:
- Page - holds the name of a page in the wiki
- String - holds standard, non-wikitext text
- Text - holds standard, non-wikitext text; intended for longer values
- Integer - holds an integer
- Float - holds a real, i.e. non-integer, number
- Date - holds a date without time
- Start date, End date - Similar to Date, but are meant to Hold the beginning and end of some duration. A table can hold either no Start date and no End date field, or exactly one of both
- Datetime - holds a date and time
- Start datetime, End datetime - work like Start date or End date, but include a time
- Boolean - holds a Boolean value, whose value should be 1 or 0, or ’yes’ or ’no’
- Coordinates - holds geographical coordinates
- Wikitext string - holds a short text that is meant to be parsed by the MediaWiki parser
- Wikitext - holds longer text that is meant to be parsed by the MediaWiki parser
- Searchtext - holds text that can be searched on, using the “MATCHES” command
- File - holds the name of an uploaded file or image in the wiki (similar to Page, but does not require specifying the "File:" namespace)
- URL - holds a URL
- Email - holds an email address
Any other type specified will simply be treated as type "String".
A field can also hold a list of any such type. To define such a list, the type value needs to look like "List (delimiter) of type". For example, to have a field called "Authors" that holds a list of text values separated by commas, you would have the following parameter in the #cargo_declare call:
|Authors=List (,) of String
The description string can also have additional parameters; these all are enclosed within parentheses after the type identifier, and separated by semicolons. Current allowed parameters are:
- size= - for fields of type "Text", sets the size of this field, i.e. the number of characters; default is 300
- allowed values= - sets a field to be an "enumeration", i.e. having a finite set of allowed values, by defining the set of values, separated by commas. This is most commonly done for fields of type "String" or "Page".
- link text= - for fields of type "URL", sets text that would be displayed as a link to that URL. By default the entire URL is shown.
- hidden - takes no value. If set, the field is not listed in either Special:ViewTable or Special:Drilldown, although it is still queriable.
For example, to define a field called "Color" that has three allowed values, you could have the following declaration:
|Color=String (size=10;allowed values=Red,Blue,Yellow)
#cargo_declare also displays a link to the Special:ViewTable page for viewing the contents of this database table.
Attaching to a table
In some cases, you may want more than one template to store their data to the same Cargo table. In that case, only one of the templates should declare the table, while the others should simply "attach" themselves to that table, using the parser function #cargo_attach. This function is called with the following syntax:
{{#cargo_attach: _table=table name }}
You do not actually need this call in order for a template to add rows to some table; a #cargo_store call placed anywhere, via a template or otherwise, will add a row to a table (assuming the call is valid). However, #cargo_attach lets you do the "Recreate data" action for that template - see "Creating or recreating a table", later in this section.
Storing data in a table
A template that declares a table or attaches itself to one should also store data in that table. This is done with the parser function #cargo_store. Unlike #cargo_declare and #cargo_attach, which apply to the template page itself and thus should go into the template’s <noinclude> section, #cargo_store applies to each page that calls that template, and thus should go into the template’s <includeonly> section. This function is called with the following syntax:
{{#cargo_store: _table=table name |field 1=value 1 |field 2=value 2 ...etc. }}
The field names must match those in the #cargo_declare call elsewhere in the template. The values will usually, but not always, be template parameters; but in theory they could hold anything.
Storing a recurring event
Special handling exists for storing recurring events, which are events that happen regularly, like birthdays or weekly meetings. For these, the parser function #recurring_event exists. It takes in a set of parameters for a recurring event (representing the start date, frequency etc.), and simply prints out a string holding a list of the dates for that event. It is meant to be called within #cargo_store (for a field defined as holding a list of dates), and #cargo_store will then store the data appropriately. #recurring_event is called with the following syntax:
{{#recurring_event:start=start date|end=end date|unit=day, week, month or year|period=some number, representing the number of "units" between event instances (default is 1)|include=list of dates, to be included in the list|exclude=list of dates to exclude|delimiter=delimiter for dates (default is ’,’)}}
Of these parameters, only "start=" and "unit=" are required.
Creating or recreating a table
No data is actually generated or modified when a template page containing a #cargo_declare call is saved. Instead, the data must be created or recreated in a separate process. There are two ways to do this:
Web-based tab
From the template page, select the tab action called either "Create data" or "Recreate data". Upon selecting this action, and hitting "OK" in the page that shows up, the following will happen:
- The existing Cargo table for that template will be dropped (if it existed before).
- A new version of the table will be created.
- Every page that includes a call to that template (and thus a call to #cargo_store) will have its #cargo_store call(s) "activated", in order to re-save those row(s) to the table.
- If there are any other templates that are defined as adding to that same table via #cargo_attach, they too will get their #cargo_store call(s) "activated".
The last two processes are done through MediaWiki jobs, and depending on your MediaWiki version and configuration, they may require a call to MediaWiki’s “runJobs” script to occur.
If any templates contain #cargo_attach, they too will get a "Create data" or "Recreate data" tab. If this tab is selected and activated, it will not drop and recreate the database table itself; instead, it will only recreate those rows in the table that came from pages that call that template.
The ability to create/recreate data is available to users with the ’recreatecargodata’ permission, which by default is given to sysops. You can give this permission to other users; for instance, to have a new user group, ’cargoadmin’, with this ability, you would just need to add the following to LocalSettings.php:
$wgGroupPermissions[’cargoadmin’][’recreatecargodata’] = true;
Once a table exists for a template, any page that contains one or more calls to that template will have its data in that table refreshed whenever it is re-saved; and new pages that contain call(s) to that template will get their data added in when the pages are created.
Command-line script
If you have access to the command line, you can also recreate the data by calling the script cargoRecreateData.php, located in Cargo’s maintenance/ directory. It can be called in one of two ways:
- php cargoRecreateData.php - recreates the data for all Cargo tables in the system
- php cargoRecreateData.php –table tableName - recreates the data for the one specified Cargo table.
Additional stored fields
When the data for a template is created or recreated, a database table is created in the Cargo database that (usually) has one column for each specified field. This table will additionally hold the following columns:
- _pageName - holds the name of the page from which this row of values was stored.
- _pageTitle - similar to _pageName, but leaves out the namespace, if there is one.
- _pageNamespace - holds the numerical ID of the namespace of the page from which this row of values was stored.
- _pageID - holds the internal MediaWiki ID for that page.
- _ID - holds a unique ID for this row.
Storing page data
You can create an additional Cargo table that holds "page data": data specific to each page in the wiki, not related to infobox data. This data can then be queried either on its own or joined with one or more "regular" Cargo tables. The table is named "_pageData", and it holds one row for every page in the wiki. You must specify the set of fields you want the table to store; by default it will only hold the five standard Cargo fields, like _pageName (see above). To include additional fields, add to the array $wgCargoPageDataColumns in LocalSettings.php, below the line that installs Cargo.
There are seven more fields that can be added to the _pageData table:
- _creationDate - the date the page was created
- _modificationDate - the date the page was last modified
- _creator - the username of the user who created the page
- _fullText - the (searchable) full text of the page
- _categories - the categories of the page (a list, queriable using "HOLDS")
- _numRevisions - the number of edits this page has had
- _isRedirect - whether this page is a redirect
Once you have specified which fields you want the table to hold, go to the Cargo maintenance/ directory, and make the following call to create, or recreate, the _pageData table:
php setCargoPageData.php
If you want to get rid of this table, call the following instead:
php cargoRecreateData.php –delete
Storing file data
Similarly to page data, you can also automatically store data for each uploaded file. This data gets put in a table called "_fileData", which holds one row for each file. This table again has its own settings array, to specify which columns should be stored, called $wgCargoPageDataColumns. There are currently five columns that can be set:
- _mediaType - the media type, or MIME type, of each file, like "image/png"
- _path - the directory path of the file on the wiki’s server
- _lastUploadDate - the date/time at which the file was last uploaded
- _fullText - the full text of the file; this is only stored for PDF files
- _numPages - the number of pages in the file; this is only stored for PDF files
To store the full text of PDF files, you need to have the pdftotext utility installed on the server, and then add the following to LocalSettings.php:
$wgCargoPDFToText = ’...path to file.../pdftotext’;
pdftotext is available as part of several different packages. if you have the PdfHandler extension installed (and working), you may have pdftotext installed already.
Querying data
Querying of data within Cargo can be done via two functions, #cargo_query and #cargo_compound_query, as well as a special page, Special:ViewTable. The Special:ViewTable page provides a simple interface that lets you set the parameters for a query. The #cargo_compound function essentially calls two or more queries at the same time, then displays their results together.
#cargo_query
The #cargo_query function is essentially a wrapper around SQL, with a few modifications. It is called with the following syntax:
{{#cargo_query:tables=table1, table2, etc.|join on=table1.fieldA=table2.fieldB, table2.fieldC=table3.fieldD, etc.|fields=field1=alias1,field2=alias2, etc.|where=table1.fieldE="some value" AND/OR etc.|group by=table1.fieldG|having=table1.fieldG="some value", etc.|order by=table2.fieldF, etc.|limit=some number|intro=some text|outro=some text|default=some text|more results text=some text|format=format...additional format-based parameters}}
The first eight parameters should look fairly familiar to anyone experienced with SQL SELECT queries:
- tables= - corresponds to the FROM clause; "table=" is an alias for it.
- join on= - corresponds to the JOIN...ON clauses.
- fields= - corresponds to the SELECT clause (with the optional "alias" values corresponding to AS clauses). Its default value is "_pageName".
- where= - corresponds to the WHERE clause.
- group by= - corresponds to the GROUP BY clause.
- having= - corresponds to the HAVING clause (similar to WHERE, but applies to values computed for "groups").
- order by= - corresponds to the ORDER BY clause. Its default value is "_pageName ASC".
- limit= - corresponds to the LIMIT clause.
The next three parameters are conditional, being applied depending on whether or not there are results:
- intro= - sets text that goes right before the query results; applied only if there are results.
- outro= - sets text that goes right after the query results; applied only if there are results.
- default= - sets text that goes in place of the query results, if there are no results. The default value is "No results", in the language of the user. To not have any text appear, just set "default=".
The last set of parameters is:
- more results text= - sets text that goes after the query display, to link to additional results. The default value is "More...", in the language of the user. To not have any text appear, just set "more results text=".
- no html - specifies that the output contains no HTML; useful when embedding the #cargo_query call within some other parser function, to avoid parser errors.
- format= - sets the format of the display (see Display formats).
There can also be additional allowed parameters, specific to the chosen display format. Again, see Display formats for the possible values of both the "format" parameter and these additional parameters. Of all these parameters, "tables=" is the only required one; although if "tables=" holds multiple tables, "join on=" is required as well.
Examples
The following query gets all the cities on the current (fictional) wiki and their populations, and displays them in a table:
{{#cargo_query:tables=Cities|fields=_pageName=City,Population|format=table}}
The following query gets only cities in Asia, and displays the city name, the country name and the population, all in a dynamic, JavaScript-based table:
{{#cargo_query:tables=Cities,Countries|join on=Cities.Country=Countries._pageName|fields=Cities._pageName=City, Countries._pageName=Country, Cities.Population|where=Countries.Continent="Asia"|format=dynamic table}}
The following query gets all countries in the wiki, and the number of cities in each one that have a page in the wiki, for each country that has more than two cities; it then displays that set of numbers with a bar chart, with the highest number of cities at the beginning:
{{#cargo_query:tables=Cities,Countries|join on=Cities.Country=Countries._pageName|fields=Countries._pageName=Country, COUNT(*)|group by=Countries._pageName|having=COUNT(*) > 2|order by=COUNT(*) DESC|format=bar chart}}
#cargo_compound_query
You may want to have the results of more than one query within the same display; this is possible using the #cargo_compound_query function. The main usage for such "compound queries" is to display multiple sets of points on a map or calendar, with a different icon (in maps) or a different color (in calendars) for each set; though it’s also possible to use it to show multiple result sets within simpler formats like tables and lists. #cargo_compound_query is called by passing in the sets of parameters of one or more calls to #cargo_query, with the overall sets separated by pipes, and the internal parameters now separated by semicolons.
As an example, let’s say you want to show a map of all hospitals and banks in a city. In our map, hospitals will get a red-cross icon, while banks get a dollar sign (we’ll say that the city is in some country that uses dollars). To complicate things, on the wiki, pages for hospitals have their own category, "Hospitals", while pages for banks are part of the general category "Businesses", with a value of "Bank" for the field "Business type". Figure 16 shows an example of how such a map could appear.
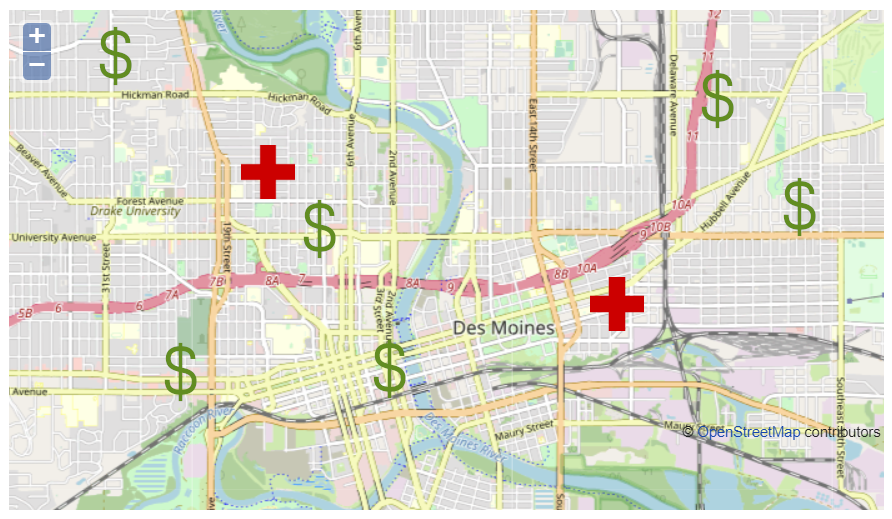
The first thing you would need to do is upload images for the icons you want to display. Let’s say you upload images for the two icons shown in Figure 16, and name them "Red cross.jpg" and "Dollar sign.png".
Here is an example call, that would show two groups of pages in a map, with a different icon for each:
{{#cargo_compound_query:table=Hospitals; fields=_pageName,Address,Coords; icon=Red cross.jpg|table=Businesses; where=Business type=’Bank’; fields=_pageName,Address,Hours,Coordinates; icon=Dollar sign.png|format=openlayers|height=200|width=400}}
Essentially, each subquery functions as its own "parameter". These subqueries have their own sub-parameters that are a subset of the allowed parameters of #cargo_query: only the parameters directly related to querying - "tables", "join on", etc. - are allowed, plus two more parameters related to display in calendars and maps: "color" and "icon". Besides the subqueries, the only allowed other parameters for #cargo_compound_query are "format", plus whatever additional parameters there are for the chosen format.
What if we want to add to our map a third set of points, for all businesses that aren’t banks, each point represented with a picture of a building? Thankfully, #cargo_compound_query makes it easy to do that: pages that are covered by more than one of the sub-queries are only displayed by the first sub-query that they apply to. So as long as the more specific queries are included before the general ones, the last query or queries can serve as a catch-all for everything that didn’t fit previously. Here’s how you could do it:
{{#cargo_compound_query:table=Hospitals; fields=_pageName,Address,Coords; icon=Red cross.jpg|table=Businesses; where=Business type=’Bank’; fields=_pageName, Address, Hours, Coordinates; icon=Dollar sign.png|table=Businesses; fields=_pageName, Address, Hours, Coordinates; icon=Office building.png|format=openlayers|height=200|width=400}}
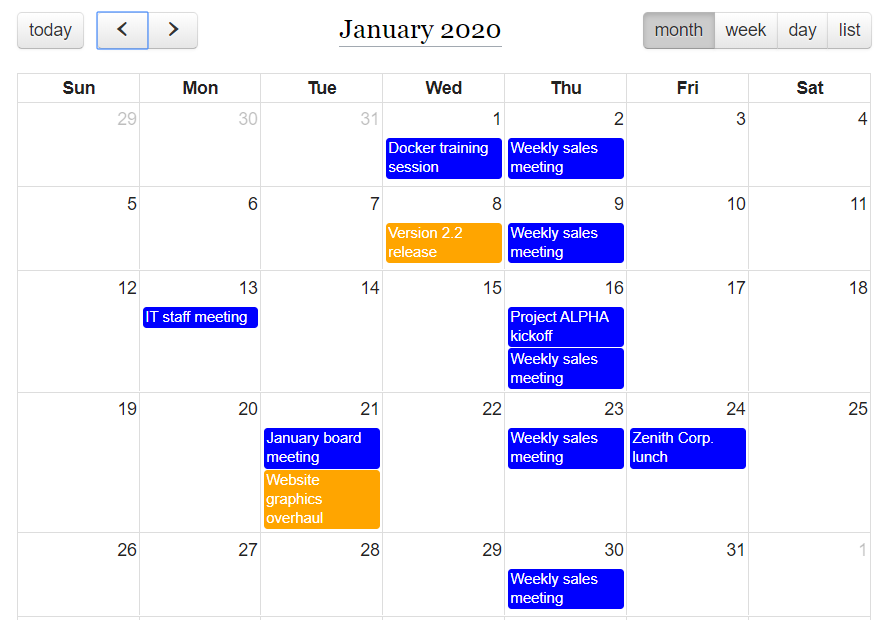
Besides maps, the other somewhat common application of Cargo compound queries is to display multiple types of events on calendars, each of which can be differently color-coded. As an example, to display meetings and task deadlines on the same calendar, with meetings in blue and deadlines in orange, you could call the following:
{{#cargo_compound_query:table=Meetings; fields=_pageName, Date; color=blue|table=Tasks; fields=_pageName, Deadline; color=orange|format=calendar|height=200|width=400}}
Figure 16 shows what such a query could generate.
The "HOLDS" command
SQL’s own support for fields that contain lists/arrays is unfortunately rather poor. For this reason, #cargo_declare creates an additional, helper table for each field that holds a list of values. Additionally, #cargo_query supports its own, SQL-like command, "HOLDS", within the "join on=" and "where=" parameters, which makes querying on such data easier. Instead of having to manually include the helper table in each such call, you can use "HOLDS" to simplify the syntax; it is what is known as "syntactic sugar" for the true, more complex, SQL. You can use "HOLDS" within the "where=" parameter to find all rows whose list field contains a certain value. To use our earlier example, if we have a table called "Books" that contains a field, "Authors", holding a list of authors, we can use the following #cargo_query call to get all books written or co-written by Leo Tolstoy:
{{#cargo_query:tables=Books|fields=_pageName=Book,Authors|where=Authors HOLDS "Leo Tolstoy"}}
This call is similar to this more complex one:
{{#cargo_query:tables=Books,Books__Authors|join on=Books._ID=Books__Authors._rowID|fields=_pageName=Book, Books.Authors__full=Authors|where=Books__Authors._value = "Leo Tolstoy"}}
Similarly, you can use "HOLDS" within "join on=" to join two tables together based on values within list fields. For example, if information about authors is stored within its own database table, "Authors", and you wanted to display a table of books, their authors, and those authors’ dates of birth, you could have the following call:
{{#cargo_query:tables=Books,Authors|join on=Books.Authors HOLDS Authors._pageName|fields=Books._pageName, Books.Authors, Authors.Date_of_birth}}
"HOLDS LIKE"
There is an additional command, "HOLDS LIKE", which maps the SQL "LIKE" command onto all of a list of values. It works just like "HOLDS". For instance, to get all books written or co-written by anyone with "Leo" in their name, you could call:
{{#cargo_query: tables=Books|fields=_pageName=Book,Authors|where=Authors HOLDS LIKE "%Leo%"}}
The "NEAR" command
Like arrays, coordinates are not well-supported overall by relational databases. For that reason, similarly to arrays, coordinates in Cargo have special handling for both storage and querying. For the case of coordinates, if you want to query on them, the recommended approach is to use the "NEAR" command, which like "HOLDS" is a virtual command, defined by Cargo. "NEAR" finds all the points near a specified set of coordinates, within a specified distance. The coordinates and distance must be placed in parentheses, separated by commas; and the distance must be in either kilometers (specified as "kilometers" or "km") or miles (specified as "miles" or "mi"). For instance, if there is a table called "Restaurants", holding a list of restaurants, and it contains a field called "Coords" holding the coordinates of each field, you could call the following query to display all restaurants (and some relevant information about them) within 10 kilometers of the Piazza San Marco in Italy:
{{#cargo_query:tables=Restaurants|fields=_pageName=Restaurant, Address, Rating, Coords|where=Coords NEAR (45.434, 12.338, 10 km)}}
Using SQL functions
You can include native functions from whichever database system you’re using within #cargo_query, in the "fields", "join on" and "where" parameters. For the sake of security, the set of allowed SQL functions is defined in a global variable, $wgCargoAllowedSQLFunctions; you can add to it in LocalSettings.php if you need one that is missing from the set.
Custom link text
You can use CONCAT() to create custom link text for both internal and external links. Example:
{{#cargo_query:table=Newspapers|fields=CONCAT( ’[[’, _pageName, ’|View page]]’ ) = Newspaper, Circulation, CONCAT( ’[’, URL, ’ View URL]’ ) = URL }}
Removing page links
Conversely, you can use CONCAT() to remove links to values, for fields of type "Page". By default, such values are displayed as links, but you may want to instead display them as just strings. The CONCAT() function is probably the easiest way to do that. If the "Author" field here is of type "Page", then to display author values as just strings, you could call the following:
{{#cargo_query:tables=Blog_posts|fields=_pageName,CONCAT(Author) }}
This works because, as long as what is being displayed is not simply the field name, #cargo_query will not apply any of that field’s special handling. If the field holds a list of values, you should instead call "CONCAT(fieldName__full)". So the call could look like this:
{{#cargo_query:tables=Blog_posts|fields=_pageName,CONCAT(Topics__full) }}
Date filtering
You can use date functions like DATEDIFF() to get items with a date within a certain range. Example:
{{#cargo_query:tables=Blog_posts|fields=_pageName,Author,Date|where=DATEDIFF(Date,NOW()) >= -7|order by=Date DESC}}
Truncating strings
You can use string functions like LEFT() or SUBSTRING() to trim strings. The following example also uses CONCAT() and IF() to append an ellipsis, only if the string value (a quote) has been truncated.
{{#cargo_query:tables=Authors|fields=_pageName=Author, CONCAT( LEFT( Quote, 200 ), IF( LENGTH( Quote ) > 200, "...", "" ) )=Quote}}
Display formats
The "format=" parameter lets you set in which format to display the results. If no format is specified, list is the default format if there is only a single field being displayed in the results, while table is the default format if there is more than one field.
The Cargo extension supports the following formats:
Lists
- list - Displays results in a delimited list.
- ul - Displays results in a bulleted list.
- ol - Displays results in a numbered list.
- category - Displays results in the style of MediaWiki categories.
More complex text displays
- template - Displays results using a MediaWiki template that formats each row of results. To apply a template, you need to create a template on the wiki that takes in values and applies some formatting to them, then add “|template=template name” to the #cargo_query call.
Here’s an example of the contents a template that could be used to display information about music albums, if the additional query printouts are for the artist, year and genre:* {{{1|}}}, {{{2|}}} ({{{3||}}}) - genre: {{{4|}}}Here’s what a query that called that template could look like, if that template were named “Album display”:{{#cargo_query:table=Albums|fields=_pageName, Artist, Year, Genre|format=template|template=Album display}}And here is the what the resulting display might look like:
- Computer World, Kraftwerk (1981) - genre: Electronic
- Crescent, John Coltrane (1964) - genre: Jazz
You can see that even simple formatting can serve to make the display of data much more legible and reader-friendly. - embedded - Shows the full text of each queried page (only the first field of the query is used).
- outline - Shows results in an outline format.
- tree - Shows results in a tree format, in which a single field defines all the relationships between "child" pages and "parent" pages.
- table - Displays results in a table.
- dynamic table - Displays results in a "dynamic" table that includes sorting, pagination and searching.

Figure 16.3: Output of a Cargo query in the “dynamic table” format
- tag cloud - Shows results in a "tag cloud" format, where the number corresponding to each string value dictates the font size for that string.
Image displays
- gallery - Displays a gallery of images, in the style of the MediaWiki <gallery> tag. The images must be files that were uploaded to the wiki; they can either be the pages that are directly queried (if the image pages call a Cargo-based template), or fields, of type "File", of other pages.
- slideshow - Displays a “slideshow” of images on the page.
Time-based displays
Numerical displays
- bar chart - Displays results in a bar chart (with horizontal bars).
- pie chart - Displays results in a pie chart.
Maps
- googlemaps - Displays results in a map, using the Google Maps service.
- leaflet - Displays results in a map, using the Leaflet library. (This format additionally lets you specify a background image as the “map”.)
- openlayers - Displays results in a map, using the OpenLayers service.
More complex displays
- exhibit - Displays results in a browsable, JavaScript-based interface. This format has many optional parameters, though its default behavior usually works fine.
Export
Five export-based display formats are defined: csv, json, excel, bibtex and icalendar.
Browsing data
Cargo provides a number of ways to generically view stored data; these are all publicly-available, but some are intended for regular users, some for administrators, and some for both.
Drill-down interface
The main mechanism that Cargo provides for browsing data is the page Special:Drilldown, which shows a listing of each table and its contents, and a set of filters for drilling down on that information. The filters are set automatically, based on the types of the fields for each table. Fields of type String and Page, plus all the number and date types, get turned into filters, with the input type used dependent on the field type; the other field types do not. (Any fields marked as "hidden" similarly will not be shown as filters.)
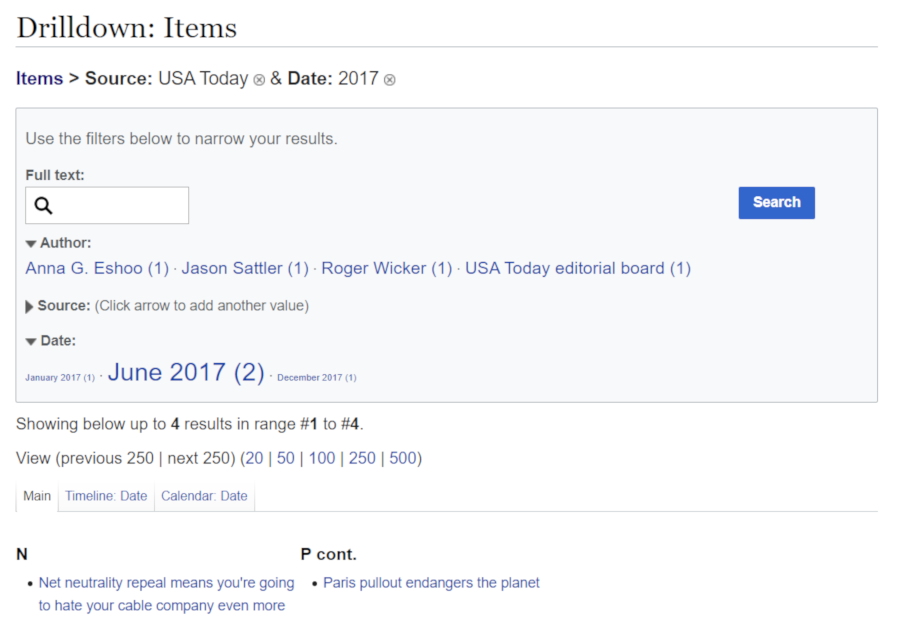
Figure 16.4: Special:Drilldown, after two filter clicks
Full-text search
As you can see in the example figure, in addition to the data filters, you can also have a text search input appear at the top which can be used in conjunction with the filters. This search input shows up if either of the following are true:
- Storage of page text is enabled; see here.
- The table being browsed has one or more fields of type "File", and storage of file text is enabled; see here.
If both are true, then the text search will search on the contents of both pages and files, and will display both.
Query form
If you go to the page Special:CargoQuery, you can see a form that allows for running a query (like #cargo_query does) by filling out the form inputs. These inputs provide help like autocompletion and validation in order to make the task easier.
Viewing tables
The page Special:CargoTables shows a listing of all tables in the wiki, and some helpful links for each one. The page does double duty: for users and administrators, it’s a convenient way of seeing the overall layout of the data; while for administrators, it’s also a sort of dashboard for maintaining all the tables. Going to that page will show a list of all the tables in the Cargo database, with links to "view" and "drilldown" (and, for administrators, “recreate data” and "delete") for each table. The "view" links will go to the page "Special:CargoTables/tableName". Clicking on any of the "view" links will show a table displaying the full contents. (Again, with the exception of "hidden" fields.) This is the same URL that is linked to from any template that declares or attaches to a Cargo table.
Values for a single page
Semantic MediaWiki
Semantic MediaWiki is an extension (really, a family of extensions) that is the main – though not the only – alternative to Cargo.
First, some background: Semantic MediaWiki is based explicitly on the Semantic Web. In the standard vision of the Semantic Web, all data is composed of “triples”: statements consisting of three parts, a subject, a predicate (i.e. a relationship) and an object. An example of this would be:
Italy Has capital Rome
Semantic MediaWiki features tagging of text within wiki pages to define such triples. The page in which the tag is placed is (usually) the subject, the tagged text is the object, and the “property” with which the text is tagged is the predicate/relationship. Until MediaWiki 1.47, the standard way to add such a triple to inline text was with syntax like the following, on a wiki page called “Italy”:
The capital of Italy is [[Has capital::Rome]].
However, with Parsoid replacing the previous (unnamed) parser within MediaWiki (see here), this SMW-specific syntax will no longer work. Instead you would need to call something like the following:
The capital of Italy is Rome.{{#set:Has capital=Rome}}
(The #set call does not output any text, unfortunately.)
Most of the time, property tags are set within templates, though, which are then editable by forms. The relevant part of an SMW-enabled infobox template, perhaps called “Country”, may look like this:
! Capital| {{{Capital|}}}{{#set:Has capital={{{Capital|}}}
And then, the page “Italy” will have a call to the “Country” template, most likely at the top, containing the following line:
|Capital=Rome
A property can have different types (Page, Text, Number, URL, etc.) and other characteristics, like its set of allowed values. These get defined within the page for each property, which is located at “Property:property-name”. So the page “Property:Has capital” might look like:
{{#set:Has type={{{Text|}}} }}
In SMW style, even the data structure is stored via properties, and as triples; pre-defined properties like “Has type” are known as “special properties”.
You can then query all the data internally, or export it externally. To query the data, SMW defines its own syntax, using the parser function #ask. This call, for instance, will display a table of countries and their capitals:
{{#ask:[[Category:Countries]] |?Has capital=Capital}}
Just as with #cargo_query, #ask has a “format” parameter that lets you set the display format of the query results. The set of allowed values for #ask and for #cargo_query are fairly similar, and in many cases the additional parameters that the corresponding parameters allow are similar as well.
That works fine for standard infobox-style data, but what if there’s more than one call to an SMW-based template on a page? In other words, what if a page contains an entire table of data? That’s not a problem with Cargo, since in Cargo each piece of data is associated with a row of a database table. In Semantic MediaWiki, on the other hand, each piece of data is by default associated with a page, so a whole table of data can’t be represented. For that, there’s the #subobject parser function. For example, what if a country has had multiple capitals, each with a different start year and end year? On the page “Japan”, either directly or via a template, there could be the following call:
{{#subobject:|Has capital=Kyoto |Start year=794 |End year=1869}}
Semantic MediaWiki’s tagging system allows for a highly flexible system of data storage, in which any property at all (including ones invented on the spot) can be added to any page. However, on SMW-based wikis where property values are only stored via templates (which is almost all of them), all of the flexibility afforded by SMW’s property tagging goes unused. The data is stored via templates, which makes it highly structured; but SMW then in turn stores it as simply a long, unordered list of semantic triples; which makes querying on the data less obvious and quite a bit slower.
There’s also the matter of maintaining all those properties. If each infobox in a template contains 10 fields, and each field is assigned a property, and you have 10 infobox templates on your wiki (these are not unreasonable numbers), then you have 100 property pages to deal with. It can quickly lead to a data structure that’s hard to either understand or modify.
Nonetheless, Semantic MediaWiki does have a user base, and you may want to use it yourself. The following subsections cover some of the extensions that are often used in conjunction with SMW. For a lot more information on SMW, and on these and other extensions, see the SMW homepage:
Other SMW extensions
The Semantic Result Formats extension defines all the more involved formats within Semantic MediaWiki. Here is the full list of result formats it defines:
- Miscellaneous: array, filtered, gallery, hash, incoming, listwidget, media, oltree, outline, pagewidget, slideshow, tagcloud, tree, valuerank
- Math: average, max, median, min, product, sum
- Export: bibtex, excel, icalendar, vcard
- Time: calendar, earliest, eventcalendar, eventline, latest, timeline
- Charts: d3chart, dygraphs, googlepie, googlebar, jqplotchart, jqplotseries, sparkline, timeseries
- Table: datatables
- Graphs: graph, process
This is a long list, although in fact most of these formats, especially the most commonly-used ones, are supported in Cargo as well.
Other notable SMW-based extensions include:
- Semantic Drilldown – defines a special page, Special:BrowseData, equivalent to Cargo’s Special:Drilldown, although for Semantic Drilldown the filters have to be defined manually.
- Semantic Compound Queries – enables compound queries via the #compound_query function – which is equivalent to Cargo’s #cargo_compound_query. Both are mostly used for displaying different sets of data within maps and calendars.
- Semantic Scribunto – enables calling SMW queries within Lua modules defined by the Scribunto extension (see page 12)
- Maps – does mapping display. It defines two SMW result formats for mapping (’googlemaps3’ and ’leaflet’), as well as #display_map (a function equivalent to Cargo’s #cargo_display_map), and several functions for dealing with coordinate data.
Wikidata, Wikibase and Abstract Wikipedia
The Wikimedia Foundation runs more than 10 additional websites besides Wikipedia, and most of them are not mentioned in this book at all. So why mention two of their sites in this book, Wikidata and Abstract Wikipedia – the latter of which has not even been released yet?
Wikidata, located at https://wikidata.org, is an extremely valuable source of data, holding over 1.6 billion facts (or “statements”, as they’re called) about over 120 million items. Its data can already be used by any wiki for both display (by External Data; see here) and data entry (by Page Forms; see here). And it has some interesting historical connections to the Semantic MediaWiki and Page Forms extensions. There is also the theoretical possibility for ambitious administrators to set up a Wikidata-like site on their own, although as we’ll see, this is generally not recommended. As for Abstract Wikipedia: though it does not yet exist, it points the way to some major changes to the entire concept of Wikipedia, and perhaps (not to try to sound too grandiose) the entire concept of formal written communication (too late!).
Some background on Wikidata: it is a massive, multilingual store of data, running on MediaWiki and a few custom-developed extensions. Its storage backend is an RDF triplestore (currently running on Blazegraph), and it can be queried with a language called SPARQL. It was launched in 2012, spearheaded by Denny Vrandečić, who brought in the funding for the project, and served as its original technical lead. Another important person in the founding of Wikidata was Markus Krötzsch, who was heavily involved in the initial design.
From the perspective of Wikipedia, the need for something like Wikidata is compelling, because populating Wikipedia requires a massive amount of data redundancy. As an illustration, let’s take a single fact: that the writer Victor Hugo was born on February 26, 1802. On any specific Wikipedia site, such as the English-language Wikipedia, this fact may be recorded in a lot of places: in the infobox in the article for Victor Hugo; in the main body of the article; in one or more category tags (“1802 births”, “19th century French authors”, etc.); in the article about the year 1802; and possibly in one or more list articles, such as (in the case of the English-language Wikipedia) “List of French novelists”. That is potentially five or more separate records that have to kept for that one fact; and that is just for a single language Wikipedia. If there is an article about Victor Hugo in twenty different languages, that may mean 100 or more records for this fact, in order for it to be fully handled. And for a clearly notable subject such as Victor Hugo, who by any standard deserves inclusion in every one of Wikipedia’s languages – and an obviously notable fact (his date of birth) – that may mean 5 * 300 = 1,500 or more places where this fact would have to be written, for it to be comprehensively recorded.
Obviously that amount of work is not achievable manually, given the potentially billions of facts that Wikipedia may hold. Thankfully, it is not really necessary either. After all, if the fact can be stored in one place, in a way that can be queried elsewhere and displayed in different languages, then perhaps most or even all of those manual entries can be removed entirely, replaced with automated queries. With enough technical infrastructure put in place, the work required to populate and maintain Wikipedia could literally be reduced a thousandfold – and languages in Wikipedia that would not conceivably have held this information before can now contain it.
You may have noticed that one of the places listed for the fact being displayed was in the article itself, i.e. as natural-language text. Does that mean that articles could be generated entirely from Wikidata’s data? Yes – and in some smaller language Wikipedias, this already happens. Of course, an article built from a few infobox-style facts is not going to make for very compelling reading; but better to have a short, somewhat stilted article than no article at all.
Wikidata is already in heavy use on Wikipedia. Many of the non-English-language Wikipedias use its data within infoboxes, by calling the #statements parser function. (This function is available only for use on Wikipedia sites; to access Wikidata data on your own site, you will have to use External Data; again, see here.) Wikidata is also used throughout all the Wikipedias, including the English-language one, to populate the “interlanguage links” between articles on the same subject across different languages. These, too, formerly had to be written manually; and a subject that had articles in 30 different languages needed to have 29 * 30 = 870 interlanguage link tags placed for it. Now all interlanguage links are handled automatically via Wikidata.
So what does Wikidata have to do with Semantic MediaWiki? For one thing, its main founders, Denny Vrandečić and Markus Krötzsch, are also the creators and initial developers of Semantic MediaWiki. This is not a coincidence: when Vrandečić and Krötzsch first created Semantic MediaWiki in 2005, they conceived it explicitly as a way to store data semantically within Wikipedia; its use on regular, non-Wikimedia wikis came only later. There were some major issues that prevented SMW from being used on Wikipedia, most importantly that it couldn’t support multiple languages (meaning that every piece of data would have to be recorded separately for each language), and that there was no way to store a reference for any piece of data. But Semantic MediaWiki can certainly be seen as the first draft of Wikidata.
Wikibase
Wikidata relies on a number of extensions, most notably two called Wikibase Repository and Wikibase Client, which are collectively called “Wikibase”. You can read about the whole system here:
Various people and organizations have attempted to make use of Wikibase on their own wikis, in order to create Wikidata-like repositories for their own data. To some extent, this is not surprising: for people who are enthusiastic about Wikidata and the promise it holds, it can make perfect sense to try to use the same software for one’s own data, with all the same opportunities for SPARQL querying, linked data, and so on. And many, or most, of these people have never heard of Cargo or SMW, so they aren’t even aware of other possibilities.
Also not surprisingly, almost all of these attempts have failed. The data entry interface for Wikidata/Wikibase is clunky, and involves a significant learning curve to understand both the concepts of Wikibase (properties, statements and the like) and the data layout in a specific wiki (which properties to populate for which page types, etc.). There is nothing user-friendly about the display of data either: just pages and pages of items and their properties, with no integration possible for non-data text.
There have been some attempts to allow inline querying of Wikibase data, so that you can, for example, show a list of all paintings made in a certain (Wikibase, by default, doesn’t even allow that). One extension, Semantic Wikibase, attempts to solve this problem by additionally storing all of Wikibase’s data in Semantic MediaWiki, from where it can be queried. Another option is to simply use the External Data extension (here), which allows you to query the wiki’s data via SPARQL and display the results.
There are similarly several options for having a drill-down interface for the data. The Wikibase Faceted Search is one such solution. If you are using Semantic Wikibase, you can then use Semantic Drilldown to filter on the data. But the nicest solution may be Anvesha, a standalone JavaScript library that is geared for Wikibase installations. You can see it in action on various sites, including Wikidata Walkabout (https://wikidatawalkabout.org/), which provides a drill-down interface for all of Wikidata, and Commons Walkabout (https://commonswalkabout.org/), which provides a drill-down interface for the “structured data” found on Wikimedia Commons.
Of course Wikibase has some advantages: its excellent support for editing in multiple languages, and its concept of storing all data as statements/assertions, which can even contradict each other without causing problems. Both of these advantages make it indispensable for Wikidata. But outside of Wikidata, even with the helper tools listed above, it would take a very specific set of requirements for the strengths of Wikibase to outweigh its weaknesses.
Abstract Wikipedia
If we’re already talking about Wikidata, we may as well also talk about the Wikimedia Foundation’s newest planned project, Abstract Wikipedia.
Even for a topic as relatively dry as a date of birth, there is a lot of nuance that simply can’t be captured in a structured data store like Wikidata. Yes, Wikidata can store that Victor Hugo was born on on February 26, 1802 – but can it record that he moved around frequently as an infant, due to his father’s military career? Clearly a more flexible, free-form type of data storage is required. That is where Abstract Wikipedia comes in: with work begun in 2020, and again spearheaded by Denny Vrandečić, it will attempt to provide a framework for long text statements about items. The text will not be stored in any natural language; rather it will be stored in a custom syntax (the details of which are still being worked out), which will make heavy use of Wikidata entity notation, especially for its “nouns”.
From this, two larger potential outcomes from Abstract Wikipedia emerge. The first is that, if the project is a success, it may simply mean... the end of Wikipedia. After all, between Abstract Wikipedia, Wikidata and Wikimedia Commons, we may have a well-referenced, universally-translateable set of text, structured data and media (such as images), respectively, on any topic. At that point, Wikipedia could basically just become an aggregator of content from these three sources, just handling things like setting the order of text and images, and providing an overall user interface. And if that happens, what really is the need for Wikipedia any more? Anyone could set up their own online “viewer” of Wikimedia content (possibly AI-powered, to any extent), with its own display of this content, arranged in its own structure, and using some translation capability – and users could easily choose whichever viewer they happened to like.
The second is that, once a syntax exists for storing text in a language-independent way, and viewing and (ideally) editing software exists for translating that syntax to and from any natural language, it could open the way to creation of a vast amount of text using this “Abstract Wikipedia syntax”, which could then be automatically translated into any language in a way more reliable (and more multi-lingual) than current machine translation allows. Will there be novels written in notational syntax? The possibilities are rather endless.